About
AI researcher focused on practical machine learning systems.

Artificial Intelligence Researcher & Machine Learning Engineer
AI Engineer at DMSLab, Konkuk University — developing and evaluating deep learning systems for computer vision, multimodal understanding, and speech synthesis.
- Affiliation: DMSLab, Konkuk University
- Location: Korea
- Degree: M.S. in AI
- Focus: CV · Multimodal · Speech
- Email: zhanglina249@gmail.com
- Languages: EN / KO / ZH
I work on end-to-end AI pipelines — from data preprocessing and model training to evaluation and deployment. Experience includes age & gender recognition, food detection on AI Hub datasets, multimodal model evaluation, historical figure TTS restoration, and image similarity research.
Research Highlights
Verifiable research and engineering output.
Research Interests
Primary areas of focus and ongoing exploration.
Computer Vision
Object detection, face analysis, age & gender recognition, and image similarity.
Multimodal Learning
Cross-modal evaluation, SLM surveys, and performance benchmarking.
Speech Synthesis
TTS systems, historical audio restoration, and speech emotion recognition.
Model Evaluation
Systematic experiment design, ablation studies, and deployment-ready pipelines.
Technical Skills
Tools and frameworks applied in research and production.
Core ML
MLOps & Infrastructure
Research Areas
Application
Projects
Selected work with problem context, methods, and open-source links.
- All
- CV
- Multimodal
- Speech
- Product

Age & Gender Recognition
Problem: Robust face attribute recognition for production scenarios.
Method: PyTorch + OpenCV pipeline with optimized architecture and training strategy.
Result: Improved recognition accuracy through model refinement and data augmentation.
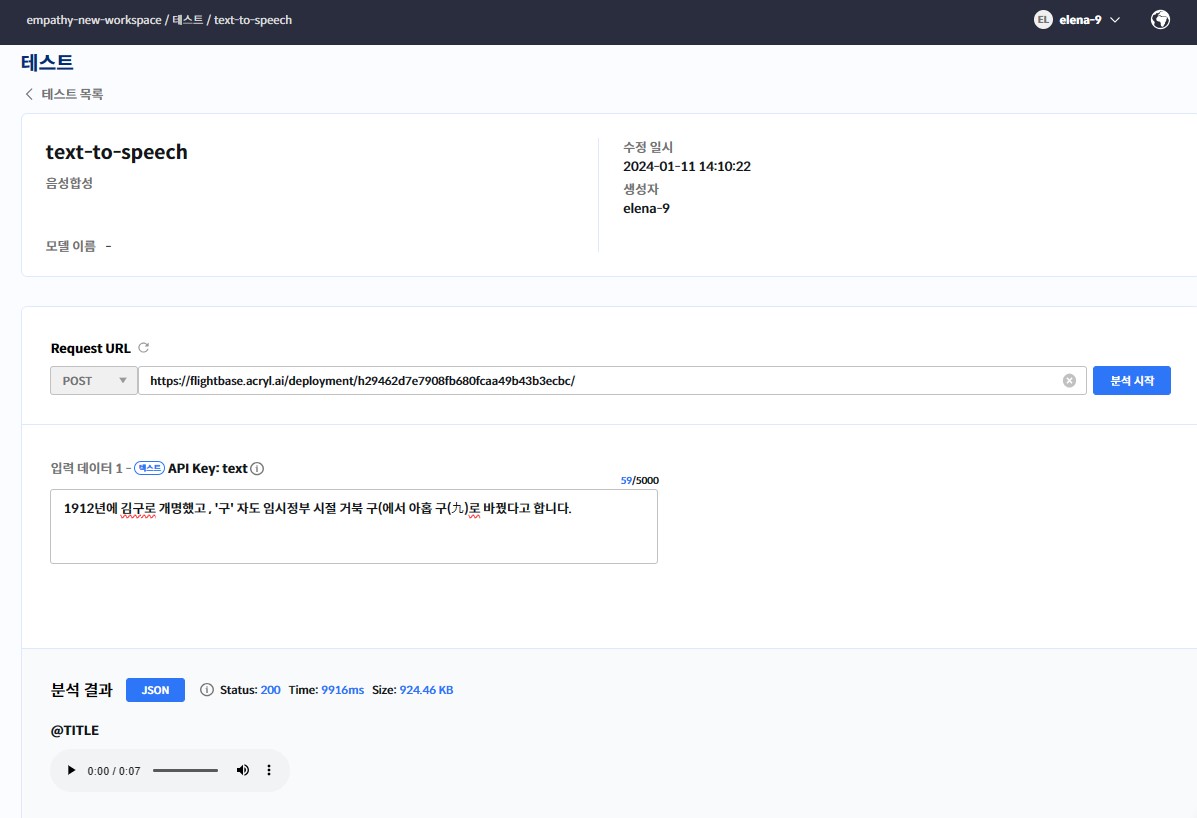
Historical Figure TTS Restoration
Problem: Restore historical figure voices from text input.
Method: MB-iSTFT-VITSv2 based TTS system with custom training pipeline.
Result: End-to-end speech synthesis for historical audio restoration use cases.
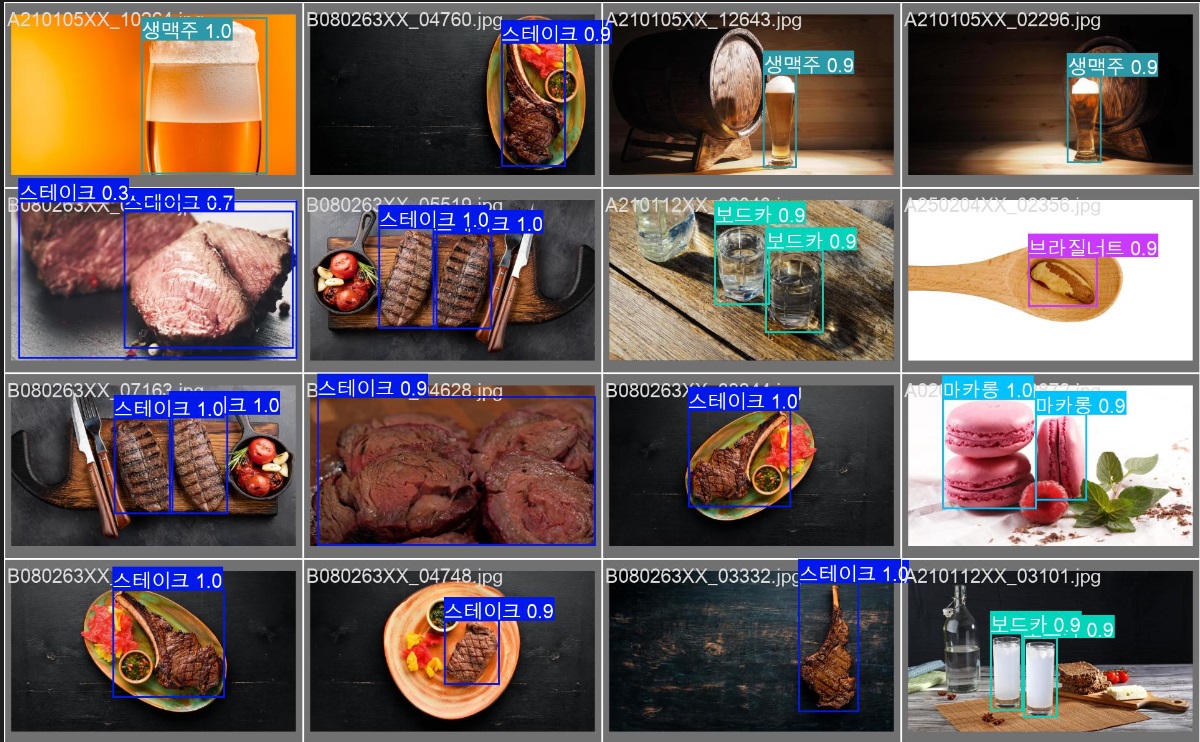
Food Detection
Problem: Detect and classify food items in real-world images.
Method: AI Hub dataset preprocessing, model training, and benchmark evaluation.
Result: Production-ready detection pipeline validated on AI Hub benchmarks.
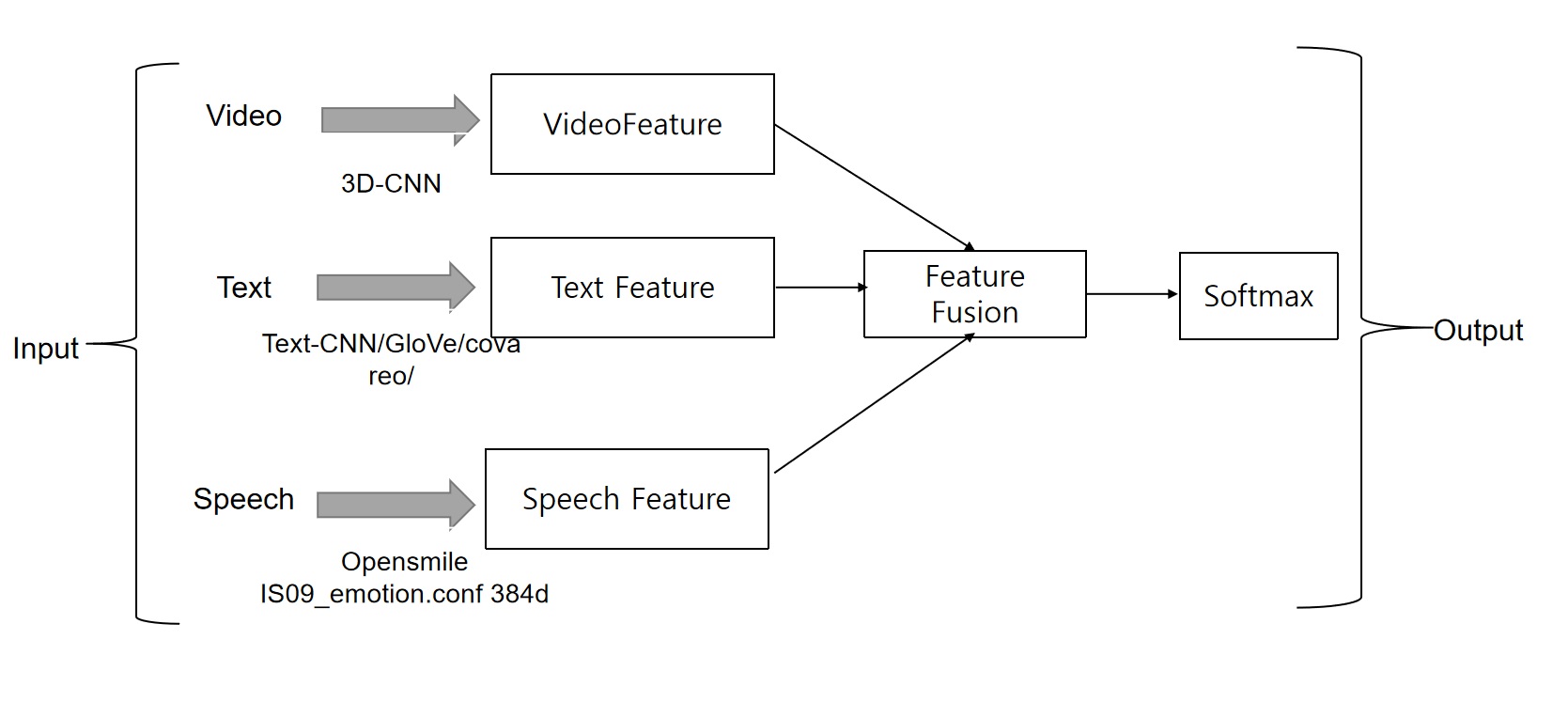
Multimodal & SLM Research
Problem: Evaluate and compare multimodal and small language models systematically.
Method: Experiment design, benchmarking framework, and curated SLM survey.
Result: Reproducible evaluation workflow and maintained reading list.
Speech Emotion Recognition Survey
Problem: Navigate the rapidly growing SER research landscape.
Method: Curated paper collection with categorization and reading notes.
Result: 2+ stars on GitHub; referenced SER resource for researchers.
Text Emotion Analysis
Problem: Classify emotional content in text data.
Method: NLP pipeline with deep learning classifiers.
Result: Baseline emotion classification models and experiment code.

LUMIÈRE — Jewelry E-commerce
Problem: Deliver a luxury jewelry shopping experience with catalog, checkout, and AI assistance.
Method: Next.js full-stack app with Stripe payments, GIA certificates, and AI concierge.
Result: Production MVP live on Vercel with curated collections and custom order flow.
Publications & Surveys
Curated technical surveys and research reading lists.
Speech Emotion Recognition Paper Survey
Comprehensive collection of SER papers with categorization. 2 GitHub stars.
Awesome Text-to-Speech List
Curated TTS papers, models, and resources for speech synthesis research.
Awesome Small Language Model List
Reading list and notes on small language models and related multimodal methods.
Awesome Code Generation List
Curated resources for code generation and program synthesis research.
Resume
Education and professional experience. CV available upon request.
Summary
AI Engineer & ML Engineer
Building practical AI systems across CV, multimodal, and speech domains.
- zhanglina249@gmail.com
- Korea · EN / KO / ZH
Education
Master of AI, Konkuk University
2019 – 2021
DMSLab, Rochester Institute of Technology collaboration, Korea
Research focus: computer vision and multimodal learning.
Bachelor of Computer Science
2012 – 2016
Changchun University, China
Computer Science and Technology.
Professional Experience
AI Research Lab
2021 – Present
Researcher
- Age & gender recognition — improved model accuracy via architecture optimization and training pipeline refinement
- Food detection — built preprocessing, training, and evaluation pipeline on AI Hub datasets
- Multimodal models — designed experiments and analysis framework for performance evaluation
- Historical figure TTS — developed MB-iSTFT-VITSv2 based speech synthesis for audio restoration
- Image similarity — researched and developed novel models and methodologies
Open Source
Featured repositories on GitHub.
MB-iSTFT-VITSv2 based text-to-speech system for voice synthesis.
Speech Emotion Recognition paper survey — 2 stars.
Curated small language model reading list and research notes.
TTS papers, models, and tools collection.
Face analysis and emotion-related CV experiments.
Text-based emotion classification models and experiments.
Blog & Writing
Technical notes, tutorials, and research reading.
Contact
Open to research collaboration and ML engineering opportunities.